This chapter discusses the Data Repository. In this section:
Overview
Parasoft’s Data Repository is designed to help teams define, extend, and review large and/or hierarchical data sets for use in Parasoft messaging tools. The same data sets can be used for service virtualization in Parasoft Virtualize and for API testing in Parasoft SOAtest. They can also be used from Parasoft CTP.
Once a repository is established on a data repository server, it can be populated from existing data sources and/or updated manually. Through the graphical representation of hierarchical data, you can review and extend the repository structure and contents. Records from one data set can be referenced in other data sets to simplify editing and management of large data sets with a high level of data reuse.
The following is a very brief overview of the key components involved in working with Parasoft’s Data Repository.
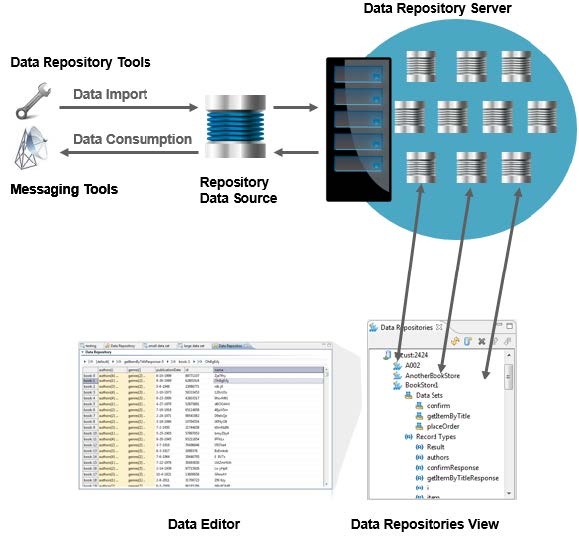
Your group can deploy any number of Data Repository Servers. Each Data Repository Server hosts any number of repositories. A repository can be populated by importing data from an existing data source; you can also manually define, extend, and edit it using the graphical Data Repositories View and Data Editor.
The Data Repositories view is your main control point for managing servers and adding, deleting, editing, and reviewing repositories on each of those servers. Each repository’s hierarchy is represented graphically, and this graphical representation links to a Data Editor that simplifies extending and browsing large, complex data sets.
The data stored in repositories can be consumed by SOAtest and Virtualize messaging tools via connection to a Repository Data Source. This allows you to take advantage of Parasoft’s form parameterization platform, as well as data group functionality.
Concepts and Terminology
When working with the Data Repository, it’s helpful to understand the following key concepts and terms:
Data Repository Server
The Data Repository Server is the server that stores the data. You can deploy a single server that multiple teams can share, or deploy multiple servers so that each team has its own sandbox.
You can download the Data Repository server from the Parasoft customer portal. This allows you to quickly create parameterized assets for use on your local system.
Additionally, remote Data Repository Server can be installed on any systems; a remote server does not need to be installed on a system where you have Parasoft Virtualize or Parasoft SOAtest installed. This server can be shared across teams or divisions.
Each Data Repository Server can host multiple Data Repositories.
See Installing a Remote Data Repository Server for installation instructions.
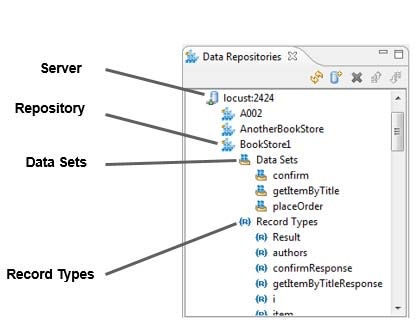
Data Repository
A Data Repository is a group of related data sets that are stored on a Data Repository Server. Each repository has one or more data sets which share a distinct library of record types. Import and export occurs at the data repository level.
The scope of a data repository is entirely up to you. It can be extremely broad, or very specific. As you structure repositories, consider the record types that will need to be shared as well as the export/import and backup/restore cycles. For instance, you might want to create one repository for services that share the same record types, and a different one for services that use a very different set of record types. For another example, assume you have two teams: one that will be frequently modifying data then restoring the original data, and another set of teams that needs continuous access to a stable version of that same data set. In that case, it would probably make sense to have 2 different data repositories.
Not all data repositories have to be represented in every team member’s Data Repositories view. For example, assume your division is sharing a Data Repository Server that hosts 20 repositories. Members of Team A might only be working with 3 of those repositories, so they would need only those 3 repositories connected to their Data Repositories view. Another team might choose to connect to 1 of those repositories along with 5 additional repositories.
Data Set
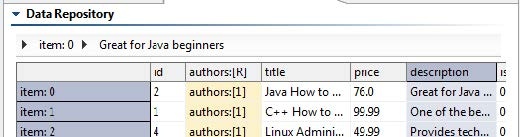
A data set is a subset of data records. The various data sets on a repository all tap into the same library of record types. For instance, if multiple data sets in a data repository use the record type "book," they will all access the same instance of the book record type. Each data set always has at least one record type.
SQL Data Set
The SQL Data Sets node contains SQL data sets, which are designed for parameterizing SQL Responders. They are automatically added when creating parameterized SQL responders from recorded database queries. Each added database data set will be labelled according to the name previously- provided for that database (via the Parasoft JDBC Driver).
This node will display only if SQL data sets are available in the given repository.
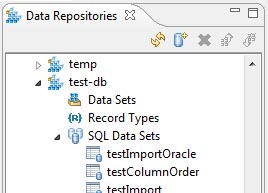
Double-clicking one of these SQL data set nodes will open the associated data editor.
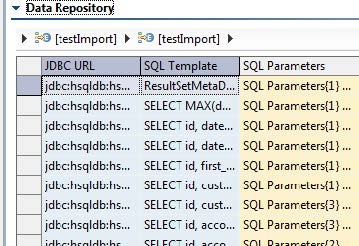
For details on how to create SQL Responders that are parameterized from data repositories, see Creating SQL Responders from a Database Recording. For details on how to edit such SQL Responders, see Editing Data Stored in a Data Repository.
Record Type
A record type has a name, a certain number of columns (a.k.a. fields), and a hierarchy defined. The scope of record types is at the repository level (e.g., the same "book" record type definition applies across all data sets that use the "book" record type).
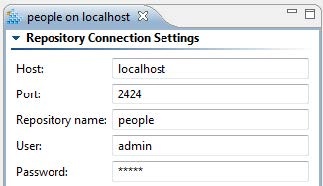
Repository Connection
A Repository Connection adds a Data Repository to the Data Repositories view, which helps you review and edit the structure and contents.
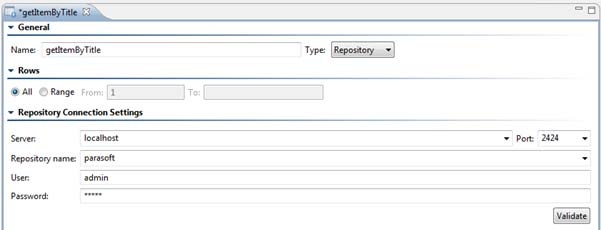
Repository Data Source
A repository data source is a "wrapper" for the repository data source that allows you to consume it in Parasoft messaging tools—in the same manner as you would consume data from an Excel data sheet, CSV file, or other supported data source. Through the data source wrapper, you can segment what repository data you want to use for a given suite (for instance, only certain rows). You can also create "data groups." With data groups, you can group similar sets of data (such as development environment test data and load/performance test data), then easily switch which data set is used at any given time— without having to edit the tool or data source configurations.
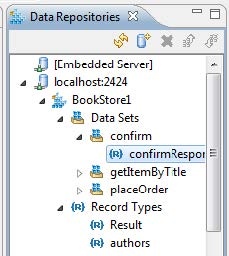
Data Repositories View
The Data Repositories view provides a UI for reviewing and editing data repositories. It can be used to create new repositories as well as to view and navigate through existing ones.
Double-clicking a node in the Data Repositories view opens the related records in the Data Editor.
Note that the icon to the left of the repository label indicates the repository status. A full-color icon indicates that the repository is available (i.e., the server hosting it is running). A grayed-out icon indicates that the repository is not available (i.e., the server hosting it is not running).
Icons also alert you if a repository is locked—and if so, by which user. For example, the following screenshot shows a repository locked to the user "cynthia". Locking repositories requires authentication through Continuous Testing Platform (CTP).
To show the Data Repositories view, choose Parasoft> Show View> Data Repositories.
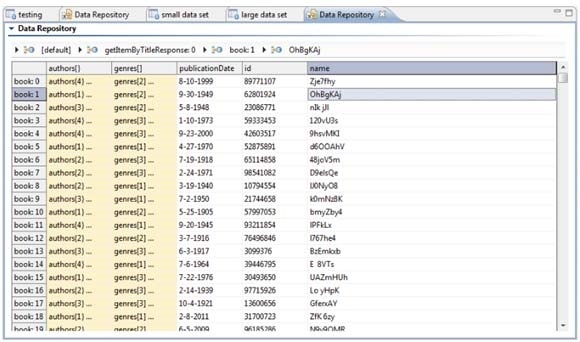
Data Editor
The data editor allows you to review and extend the repository structure and contents.
Structure Requirements
The structure of the repository is up to your team. The only requirements are:
- Message parameterization: Using a repository data source, you can parameterize messages with sequences or elements with varying numbers of items. Sequences or elements that are of option type or of abstract/concrete schema types cannot be parameterized using repository data.
- At least one key column: Key columns are used for data source correlations within Message Responders (in the Data Source correlations tab). You can have multiple key columns (e.g., if you have 3 parameters in the data source correlation and want to parameterize each with a separate column from the repository, you would need at least 3 key columns).