可以在多个级别上添加数据源:
- 响应器套件或操作套件
- 测试套件
- 项目
全局 (要求验证许可证)
数据源级别越高,共享的范围就越广。例如,如果希望添加一个只适用于特定测试套件、响应器套件或操作套件的数据源,则在套件级别进行添加。如果要在项目中跨套件共享,请在项目级别添加。如果要在多个项目中共享,则在全局级别添加。
全局和项目级别的数据源可以重复使用,并且在单个项目文件之外共享。它们保存在属性文件中,该属性文件可以检入/检出源码控制(如果使用源码控制),以便共享。全局数据源保存在单个属性文件中,可以在首选项面板(位于首选项> Parasoft> 全局数据源)中进行定义。项目级别数据源保存在 Eclipse 项目目录下的 .parasoft 文件中。如果正在进行负载测试,请注意,Load Test 工具当前不支持全局数据源。引用全局数据源的测试套件可以通过复制粘贴全局数据源到 SOAtest 项目的跟测试套件中来进行弥补。若要添加数据源
- 请执行以下任一操作:
- 针对套件级别数据源,请选择相应套件节点,然后点击工具栏中的添加数据库
 。
。 - 针对项目级别数据源,右键点击相关项目的测试用例浏览器或虚拟资产浏览器节点,然后选择新建> 数据源。
- 针对全局级别数据源,右键点击全局数据源节点,然后选择新建> 数据源。
- 针对套件级别数据源,请选择相应套件节点,然后点击工具栏中的添加数据库
- 选择数据源类型,然后点击完成。对于 Bean Wizard,请点击下一步。数据源添加完成后,将打开对应的配置面板,并在相应的数据源分支中显示。将为每个可用的数据源添加一个节点。
- 按照以下说明,配置该数据源:
配置资源库数据源
Parasoft 的数据资源库旨在帮助团队定义、扩展和查看大型和/或层次数据集,以便在 Parasoft 消息工具中使用。有关配置资源库数据源的详情,请参阅使用大层次数据集。
配置 CSV 文件数据源
若要配置 CSV 文件数据源:
- (可选)更改名称字段中的数据源标签。
- 使用行控件,以指明要使用行的范围。
- 如果只希望使用所选行,请启用范围,然后通过将值键入到从和到字段中,输入所需范围(假定索引从一开始)。例如,若只使用前 10 行,在从字段输入 1,到字段输入 10。若只使用第五行,在从字段输入 5,到字段输入 5。
在文件路径字段中指定 CSV 文件的路径。可以使用以下变量:
test_suite_loc: 相对于 .tst 或 .pva 文件的文件路径。例如:${test_suite_loc}/../files/myCSVFile.csv
project_loc: 项目的相对路径。例如:${project_loc:MyProject}/myCSVFile.csvworkspace_loc:SOAtest 工作空间的相对路径。例如:${workspace_loc}/../files/myCSVFile.csv还可以使用环境变量。请参阅在测试中使用环境变量和配置虚拟化环境。- 指定文件使用的分隔符和引号的类型。
- 如果需要,更改其他选项:
- 删除前导/尾随空格:指定是否删除值开始和结尾处出现的空白。
- 第一行指定列名:指定是否考虑将 CSV 文件第一行作为列名。如果第一行指定列名,则表单 XML 中的元素将列名显示为每个值的名称。 如果第一行未指定列名,则表单 XML 中的元素将“value”显示为每个值的名称。
- 如果希望查看该数据源中列的列表,点击显示列。第一行值被识别为列标题。如果希望使用不同的列标题,请更新数据源的第一行,然后点击显示列。
配置数据库数据源
必须指定连接到数据库的 JDBC 驱动器。 详情请参阅配置 JDBC 驱动程序。
- (可选)更改名称字段中的数据源标签。
- 使用行控件指明行的使用范围。可以启用范围并指定行的具体范围(索引从一开始)。例如,若只使用前 10 行,在从字段输入 1,到字段输入 10。若只使用第五行,在从字段输入 5,到字段输入 5。默认指定所有数据库行。
- 从下拉菜单中选择驱动器类,并配置数据库连接设置。有关配置常用数据库连接的详情,请参阅配置 JDBC 驱动程序。如果在下拉菜单中没有看见您的驱动类,请选择自定义。
点击显示列如果要检查使用了哪些列名。
已有的行若要使用不同的行标题,请更新数据库列名,然后点击显示列。
如果希望使用不同的行,请更新 SQL 查询以检索适当的列,然后点击显示列。
配置数据库关联数据源
与数据库数据源不同,数据库关联数据源允许您禁用缓存,因此虚拟资产无需重新部署即可读取新记录。这使得 SQL 关联数据源十分适合 CRUD 工作流。
必须指定连接到数据库的 JDBC 驱动器。 详情请参阅配置 JDBC 驱动程序。
- (可选)更改名称字段中的数据源标签。
在SQL 查询字段中,输入要加载数据的 SQL 语句。该语句必须指定一个关联键,用于数据源关联性选项卡中消息响应器内的数据源关联性。该关联键的声明格式如下:
DatabaseColumnName=:CorrelationKeyName.例如:SELECT * FROM Customer WHERE ID = :CustomerID;
以上声明选择客户表中 ID 列具有“CustomerID”关联键指定值的所有行列。
- 在关联键表中,点击添加,定义用于消息响应器中数据源关联性的关联键。该表将自动填入 SQL 查询中声明的任何关联键,但您可能需要为该键设置正确的类型。根据所选类型指定样本值。对于某些数据库,可能需要将样本值设置为有效的数据库值,以检索所需的数据库列。选择一列并点击修改进行更改。
- 请注意,表中配置的所有关联键必须在消息响应器的数据源关联性选项卡中配置。
- 如果想让数据库的更新立即反映在使用相应数据的已部署虚拟资产中,则需禁用启用缓存选项(默认已禁用)。启用后,虚拟资产需要重新部署,以使更改在运行时生效。为了优化性能,建议为负载测试启用缓存。
- 列字段显示可根据 SQL 查询用于参数化的数据库列。如果要使用不同的列,请更新 SQL 查询并点击显示列。
配置 Excel 电子表格数据源
若要配置 Excel 表数据源:
- (可选)更改名称字段中的数据源标签。
- 使用行控件,以指明要使用行的范围。
- 如果只希望使用所选行,请启用范围,然后通过将值键入到从和到字段中,输入所需范围(假定索引从一开始)。例如,若只使用前 10 行,在从字段输入 1,到字段输入 10。若只使用第五行,在从字段输入 5,到字段输入 5。
在文件路径字段中指定 Excel 文件的路径。可以使用以下变量:
test_suite_loc: 相对于 .tst 或 .pva 文件的文件路径。例如:${test_suite_loc}/../files/myspreadsheet.xlsproject_loc: 项目的相对路径。例如:${project_loc:MyProject}/myspreadsheet.xls还可以使用环境变量。 例如,
${project_loc:MyProject}/DataSource/${soa_env:XLS_DIR}/myspreadsheet.xls。请参阅在测试中使用环境变量。请参阅在测试中使用环境变量和配置虚拟化环境。
- 从工作表菜单中选择要使用的特定 Excel 文件的工作表。
- 如果希望 SOAtest 将 Excel 数据源中每一列的大小限制为行数最少的一列的大小(换句话说,如果希望在遇到空单元格时停止处理数据),则启用在第一个空行处停止处理电子表格。
重要项:SOAtest 假定第一行值代表行标题。如果不是这样的话,可能会导致您在 SOAtest 中标识和选择数据源行时出现问题。如果希望 SOAtest 使用不同的列标题,请更新第一行数据源,然后点击显示列。
配置表数据源
若要通过输入或粘贴数据源值到内部表编辑器中来指定数据源值:
- (可选)更改名称字段中的数据源标签。
- 使用行控件,以指明要使用行的范围。
- 如果只希望使用所选行,请启用范围,然后通过将值键入到从和到字段中,输入所需范围(假定索引从一开始)。例如,若只使用前 10 行,在从字段输入 1,到字段输入 10。若只使用第五行,在从字段输入 5,到字段输入 5。
- 如果希望指定列名(而不是使用默认的 A、B、C、D 等等),请选择第一行指定列名。
- 通过键入或粘贴数据源值到表中来添加数据源值。可以复制像 Excel 这样的流行工作表。注意,表编辑器包括标准的复制、剪切、粘贴编辑命令(当选中单元格时),以及插入行或表的命令。若要添加更多的行,请使用向下箭头键或向下箭头滚动条按钮。若要添加更多的列,请使用向右箭头键或向右箭头滚动条按钮。
配置组合多个数据源的聚合数据源
可以创建聚合数据源。在该数据源中,您可以将其他可用数据源的值组合到单个数据源中。如果想执行需要绘制来自不同数据源的值的功能测试,这一点尤其有用。例如,在向服务器发送请求的过程中,您可能希望发送包含用户信息(如姓和名)的数据源中的值,也可能希望发送包含用户登录和密码信息的单个数据源中的值。 通过将两个数据源合并到一个聚合数据源中,您可以创建一个测试,而不必为每个数据源创建单独的测试。
关于聚合数据源如何与数据组之间进行比较的讨论,请参阅 了解 SOAtest 中的数据组和聚合数据源和/或了解 Virtualize 中的数据组和聚合数据源。若要将多个数据源合并到一个聚合数据源中:
- (可选)更改名称字段中的数据源标签。
- 使用行控件,以指明要使用行的范围。
- 如果只希望使用所选定行,请点击范围按钮,然后通过将值键入到从和到字段,输入所需范围(假定索引从一开始)。例如,若只使用前 10 行,在从字段输入 1,到字段输入 10。若只使用第五行,在从字段输入 5,到字段输入 5。
- 从可使用框中选择所需数据源,然后点击添加,将它们添加到已选择框中。
- 可使用框包含添加到测试套件或响应器套件的所有数据源。选择并将所需数据源添加到已选框之后,已添加数据源中包含的列名在列框中显示。
配置允许在多个数据源之间切换的数据组数据源
数据组包含相似数据源的数量,该数据源至少有一列相同;它允许您选择在任何给定时间应用哪个数据组。如果要为同一工具动态指定不同的数据源,这一点尤其有用。运行时,在不需编辑工具或数据源的情况下,您可以快速切换使用哪个数据源。若要使用数据组,需要将具有共享列的数据源分组在一起,然后指定应该让哪个数据源活跃。有关数据组与聚合数据源比较的内容,请参阅了解数据组和聚合数据源以及了解数据组和聚合数据源。若要将多个数据源合并到一个数据组中:
- (可选)更改名称字段中的数据源标签。
- 使用行控件,以指明要使用行的范围。
- 如果只希望使用所选行,请启用范围,然后通过将值键入到从和到字段中,输入所需范围(假定索引从一开始)。例如,若只使用前 10 行,在从字段输入 1,到字段输入 10。若只使用第五行,在从字段输入 5,到字段输入 5。
- 从可使用框中选择所需数据源,然后点击添加,将它们添加到已选择框中。
- 可使用框包含添加到测试套件或响应器套件的所有数据源。
- 如果数据源与当前选定数据源没有任何共同的列,则无法添加。
- 如果添加数据源将减少整个数据源中共享列的数量,则将显示一个警告。
- 选择并将所需数据源添加到已选框之后,所有选定数据源中出现的相同列都将在列框中显示。
在活动数据源下指定要使用的数据源。也可以根据活动环境选择组的活动数据源。可以将环境变量(使用
${var_name}符号)输入到活动数据源字段中,并指定运行时所需环境。 有关在命令行或在 UI 中使用运行时环境的详细信息,请参阅在不同的环境中配置测试和配置虚拟化环境。
配置文件数据源
若要配置文件数据源:
- (可选)更改名称字段中的数据源标签。
- 使用行控件,以指明要使用行的范围。
- 如果只希望使用所选行,请启用范围,然后通过将值键入到从和到字段中,输入所需范围(假定索引从一开始)。例如,若只使用前 10 行,在从字段输入 1,到字段输入 10。若只使用第五行,在从字段输入 5,到字段输入 5。
- 指定从哪个文件或目录中导入文件。指定位置中可用的所有文件都将显示在表中。右键点击选项还有剪切、复制和粘贴值操作。
- 若要过滤文件数据源使用的文件,请在文件过滤器字段中输入字符串。例如:
- * = 任何字符串的通配符
- *.*= 所有文件(默认)
- *.txt = 所有文本文件
- data* = 所有文件名以“data”开始的文件
- data*.txt = 所有文件名以“data”开始的文本文件
- *data* = 所有文件名包含字符串“data”的文件
- 若要过滤文件数据源使用的文件,请在文件过滤器字段中输入字符串。例如:
- 如果希望文件数据源使用文件数据源时导入目录中的所有文件,请启用基于上次导入动态刷新选项。如果不启用该选项,则文件数据源将只使用文件数据源表中所列出的文件,即使导入目录中存在其他文件。为确保 .tst 文件的可移植性,在以下情况中必须启用该选项:
- 当 .tst 文件需要在多台机器上执行时。
- 当 .tst 文件将在使用多个 Load Test 生成器机器的负载测试中使用时。
在运行时,每个文件的内容都用作数据源值。
配置可编写数据源
为了在后续测试中重复使用数据源,配置一个捕获运行时数据的可编写数据源:
- (可选)更改名称字段中的数据源标签。
- 使用行控件,以指明要使用行的范围。
- 如果只希望使用所选行,请启用范围,然后通过将值键入到从和到字段中,输入所需范围(假定索引从一开始)。例如,若只使用前 10 行,在从字段输入 1,到字段输入 10。若只使用第五行,在从字段输入 5,到字段输入 5。
- 指定编写到数据源的首选编写模式。可以选择以下其中一项:
- Set-Up 测试模式> 附加:如果希望 Set-Up 测试在以前编写的任何值之后附加新数据,选择该选项。这是默认的模式。只有 Set-Up 测试才能以这种模式编写入数据源。
- 标准测试模式> 覆写:如果希望标准测试(非 Set-Up 测试)使用新数据重写之前编写的任何值,请选择该选项。只有标准测试才能以这种模式编写入数据源。
- Set-Up 测试模式> 附加:如果希望标准测试(非 Set-Up 测试)在以前编写的任何值之后附加新数据,请选择该选项。只有标准测试才能以这种模式编写入数据源。如果启用该选项,还可以指定重置频率设置,指定数据源将如何重置(清除)之前编写的数据。
- 每次迭代:配置数据源,以每次它所在的测试套件或响应器套件开始遍历新数据源行时进行重置。
每次写入访问:配置数据源,以在每个新的写入访问(只适用于在单个写入访问中附加数据)之前进行重置。
- 如果希望指定列名(而不是使用默认的 A、B、C、D 等等),请启用第一行指定列名。
- 为可写数据源设置填充(例如,使用数据库工具向其写入数据)。
例如,在 Virtualize 中填充可编写数据源的一个方法是:
- 添加 XML 数据库工具作为工具输出。
- 练习该套件以填充 XML 数据库。
- 向 XML 数据库 GUI 中选择的 XPaths 添加一个节点。
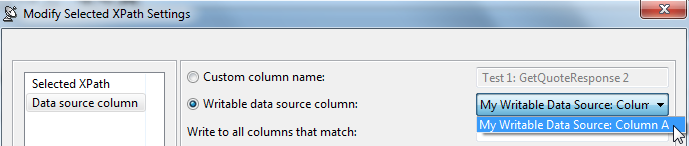
- 双击 XML 数据库 GUI 中数据源列名列下的条目行。将打开修改对话框。
- 选择位于左侧的数据源列,然后选择位于右侧的可写数据源列,指定要包含存储值的列名。
在该示例中,对于 SOAtest,这个过程将非常类似:
- 将 SOAP 客户端工具作为 Set-Up 测试添加到测试套件。有关设置的更多信息,请参阅添加 Set-Up 和 Tear-Down 测试。
- 将 XML 数据库工具作为输出添加到 SOAP 客户端 Set-Up 测试。
- 运行 SOAP 客户端 Set-Up 测试,以填充 XML 数据库。
- 向 XML 数据库 GUI 中所选元素列添加一个节点。
- 双击 XML 数据库 GUI 中数据源列名列的条目行。将打开修改对话框。
- 选择可写数据源列,点击 OK。现在,当运行 Set-Up 测试时,将填充可编写数据源。每次运行父测试套件时,可编写数据源将会自动重置。
注意
使用 Bean Wizard 配置数据源表单 Java Bean 字段
请参阅Using Interpreted Data Sources。
设置“一对多”数据源映射关系
您还可以设置 SOAtest,将一个数据源(例如,包含登录信息的全局数据源)的单行值与另一个数据源的多行值结合使用,操作如下:
- 添加可编写数据源,然后按照Configuring a Writable Data Source中的说明配置。可编写数据源允许 SOAtest 独立于其他数据源进行迭代。
- 如果数据源中存在多个“global”参数,则右键点击单个可编写数据源列并选择插入列。将列重命名为与原始数据源列匹配的内容。
- 添加扩展工具作为 Set-Up 测试(详情请参阅添加 Set-Up 和 Tear-Down 测试)。这将充当到您的“全局”数据源的接口。
按照用于自定义脚本的扩展工具中所描述配置此扩展工具。假定要访问的列名为数据源“凭据”中的“用户名”和“密码”,您将在工具配置面板中选择凭据数据源,并选择使用数据源,然后添加以下代码:
from soaptest.api import * def getCredentials(input, context): username = context.getValue("Credentials", "username") password = context.getValue("Credentials", "password") return SOAPUtil.getXMLFromString( [ username, password ] )- 右键点击扩展工具并选择添加输出,然后选择 XML 数据库工具选项将 XML 数据库链接到扩展工具输出。
- 运行测试一次,以填充 XML 数据库。
- 双击 XML 数据库工具,打开配置面板。
- 选择与第一个参数相对应的元素,点击添加。
- 点击修改,选择数据源列名。
- 选择可写数据源列,然后选择相应的名称。
- 对与第二个参数相对应的元素重复步骤 8-10。