本主题解释如何将数据库记录从 Parasoft JDBC 驱动程序转换为带有 SQL 响应程序的虚拟资产。
本章包含:
概要
Virtualize 提供了一个向导,用于为使用 Parasoft JDBC 驱动程序创建的数据库记录创建和部署 SQL 响应程序(如 使用 Parasoft JDBC 驱动程序中所述)。这些数据库记录捕获数据库查询及其相应的结果。
Virtualize 将创建一个 SQL 响应程序来处理特定 JDBC URL 的 SQL 查询。当 SQL 响应程序接收到一个查询时,它会尝试将其与一组可用的查询模板进行匹配。如果找到匹配,则使用相关的结果集作为响应。用于匹配查询并提供相关响应的数据可以保存为数据存储库或 .csv 文件。
存储库驱动的 SQL 响应器与 CSV 驱动的 SQL 响应器
Virtualize 为从数据库记录生成 SQL 响应程序提供了两个选项:
- 存储库驱动 的 SQL 响应器通过在 Parasoft 数据存储库中定义的查询模板和结果集自动参数化(使用此选项时也会自动创建该存储库)。此选项允许您使用为操作大型复杂数据源而设计的图形界面快速添加和修改查询模板和响应。数据值的存储和操作独立于 SQL 响应器工具和 .pva。
- .CSV驱动 的 SQL 响应器在SQL 响应器工具接口中直接指定查询模板;相关的结果集存储在 .csv 文件中。
创建存储库驱动的 SQL 响应程序
前提条件
在可以开始创建存储库驱动的 SQL 响应程序之前:
- 您的团队必须安装并运行数据存储库服务器。有关更多详情,请查阅 安装远程数据库服务器。
- 必须能够访问正在运行的 Virtualize 服务器,该服务器托管要为其创建 SQL 响应程序的数据库记录文件。
监视控制台视图
在创建 SQL 响应程序时,保持控制台视图可见是很有帮助的。此视图将显示在处理数据库记录的文件时生成的任何警告、错误和信息消息。
若要自动创建和部署存储库驱动的 SQL 响应程序:
- 请右键单击 VirtualAssets 项目,然后选择 Add New> Virtual Asset (.pva) 文件。

- 输入文件名,然后单击 Next。
- 选择 Recorded Database Queries,然后单击 Next。
- 如下完成记录数据库查询向导页面:
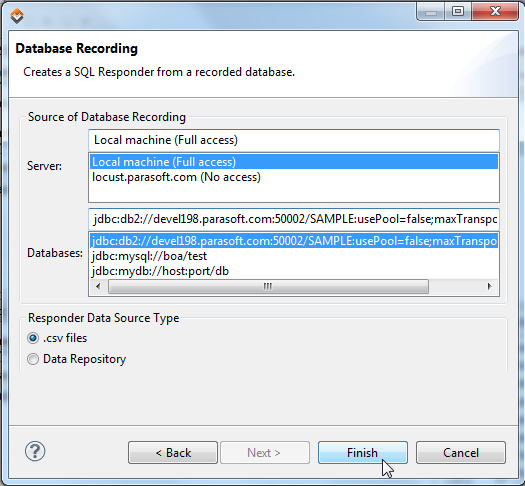
- 对于 Server,请选择数据库记录文件所在的 Virtualize 服务器。
- 对于 Databases,请从 JDBC URL 列表中选择适当的数据源。此列表根据可用的记录填充;可用的 URL 将直接虚拟化到捕获记录的适当文件集。
- 对于 Responder Data Source Type,请选择 Data Repository。

- (可选)如果想用通配符自动替换日期字段,请启用 Wildcard Date Fields。如果启用此选项,并且查询接受日期作为参数,Virtualize 将不需要精确匹配日期。我们建议在查询将当前时间或更改的数据作为输入时启用此选项,但您希望从 Virtualize 获得一致的响应(忽略 date 字段中的更改)。
- 单击 Next。
- 在 Parasoft 数据存储库设置页面中,指定哪个数据存储库应该存储用于参数化 SQL 响应器的数据,然后单击 Next。
- 从 Server 框中指定要连接到哪个服务器(嵌入式服务器或远程服务器)。 如果选择嵌入式服务器, Port、 User和 Password 字段将变灰。如果选择远程服务器, Port、 User和 Password 字段将自动被填充(如有需要,可进行调整)。
- 在 Repository name下,选择或输入要使用的资源库的名称。如果输入新存储库的名称,将创建该存储库。
- 定义存储库连接时,可以通过单击 Validate检查连接。
锁定存储库,直到向导完成
当使用远程(例如,非嵌入式)数据存储库服务器时,此处指定的存储库将被锁定,直到向导完成。如果想让锁显示为“locked by [your_username]”而不是“locked by [tmp]”,请选中 Configure authentication for locking,然后指定所使用的 CTP 服务器的 URL,以及该 CTP 服务器的用户名和密码。有关锁定的更多信息,请参见 锁定和解锁 CTP 中的存储库。
- 单击 Finish。
将创建和配置以下项目:
- 将添加一个带有参数化查询模板、结果集和参数的 SQL 响应器。
- 一个 SQL 数据集将被添加到所选存储库的 SQL Data Sets 区域。如果这个存储库还不存在,就会创建它。适用的记录类型将被添加到存储库中。
- 将为每个添加创建的数据集添加存储库数据源,并将 SQL 响应器配置为使用该数据源。

一个 .pva 将被部署到本地 /virtualDb 上的 Virtualize 服务器。

配置部署设置
有关部署设置的更多详情,请查阅 Configuring Individual Virtual Asset Deployment Settings。
创建 CSV 驱动的 SQL 响应程序
前提条件
在开始创建 .CSV 驱动的 SQL 响应程序之前,必须能够访问正在运行的 Virtualize 服务器,该服务器托管要为其创建 SQL 响应程序的数据库记录文件。
监视控制台视图
在创建 SQL 响应程序时,保持控制台视图可见是很有帮助的。此视图将显示在处理数据库记录的文件时生成的任何警告、错误和信息消息。
若要自动创建和部署 CSV 驱动的 SQL 响应程序:
- 请选择可用创建向导中的 Recorded Database Queries 选项。
有关访问向导的详细信息,请参见 添加项目、虚拟资产和响应程序套件。 - 如下完成记录数据库查询向导页面:
- 对于 Server,请选择数据库记录文件所在的 Virtualize 服务器。
- 对于 Databases,请从 JDBC URL 列表中选择适当的数据源。此列表根据可用的记录填充;可用的 URL 将直接虚拟化到捕获记录的适当文件集。
- 对于 Responder Data Source Type,请选择 .csv files。
- (可选)如果想用通配符自动替换日期字段,请启用 Wildcard Date Fields。如果启用此选项,并且查询接受日期作为参数,Virtualize 将不需要精确匹配日期。我们建议在查询将当前时间或更改的数据作为输入时启用此选项,但您希望从 Virtualize 获得一致的响应(忽略 date 字段中的更改)。
- 单击 Finish。
将创建和配置以下项目:
- 使用适当的 JDBC URL、SQL 模板和参数标准配置的 SQL 响应程序。
- 存储在 VirtualAssets 项目中的 database_recorded_data 文件夹中的一个或多个 ResultSet 文件。
- 一个 .pva 将被部署到本地 /
virtualDb上的 Virtualize 服务器。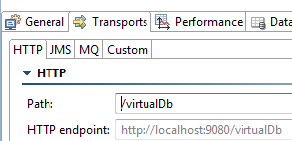
配置部署设置
有关部署设置的更多详情,请查阅 Configuring Individual Virtual Asset Deployment Settings。
自定义虚拟资产
可以通过编辑 SQL 响应程序工具配置来修改或扩展数据库行为。这一点在 SQL 响应程序中进行了描述。