In this section:
Overview
Hierarchical data sets are added to the Test Data module when transactions are recorded and added to the database during testing. You can also use the Data Repository Tool to manually import data directly into your repositories. The Test Data interface enables you to review and modify the data so that it can be used across testing scenarios.
Important Concept and Terminology
See About the Data Repository for definitions of terms used in this section.
Main Toolbar
The main application toolbar contains functionality associated with the data repository, but additional functionality may appear in the toolbar depending on the current view.

You can perform the following actions in the main toolbar.
- Click Export to create a copy of the selected data repository that can be downloaded from the main page of the Data tab. See Creating and Managing Repositories.
- Click Lock prevent other users from making changes to the selected repository. See Locking and Unlocking Repositories in CTP.
- Click Refresh to load changes made on a connected application.
- Click Data Set to begin manually adding a new data set to the selected repository. See Manually Creating a Data Set.
- Click Delete to delete the selected repository. See Creating and Managing Repositories.
Data Repository View
Click on a repository in the Data tab to open the data repository view.

You can perform the following actions in the data repository view.
Manually Create a Data Set
- Choose a repository from the server menu and click Data Set in the main toolbar.

- Specify names for the data set and record type. By default, the name of the data set is used for the record type name, but you can click in the Record Type Name field and specify a different value if your test scenarios use a specific naming convention.
- Enable the Empty option and click Create.

The data set will be added to the repository page. See Add and Modify Data for next steps.
Download Data Sets and Record Types
You can download the data set or record type as a JSON file.
- Choose Download from the ellipses menu and specify an encoding option (default is UTF-8).

- Click Download when prompted to continue.
Delete Data Sets and Record Types
Choose Delete from the ellipses menu and confirm that you want to remove the data set or record type when prompted. If the data set contains record types that do not reference or are not referenced by another component, you can enable the Delete orphaned record types option to ensure that the data set is completely removed. This option does not apply to record types.
Open the Data Record View
Click on a data set in the Data Sets column to open the Data Record View.
Data Record View
The data record view is the interface for modifying data. Click on a data set from the data repository view to access records.

You can perform the following actions.
Use the Data Sets Toolbar

- Click the refresh button to load any changes to the data.
- You can download the data as a JSON file
- Click the download icon and choose an encoding option (default is UTF-8).
- Click Download.
- Click the trash icon and confirm that you want to delete the data set when prompted. If the data set contains record types that do not reference or are not referenced by another component, you can enable the Delete orphaned record types option to ensure that the data set is completely removed.
- Enter a search term in the search field and press ENTER to search the data set. Searches return records that match the search terms exactly; enter keyword phrases to narrow your search.
Add and Delete Rows and Columns
Click on the ellipsis menu in the data set header to add key columns, value columns, and to add first and last rows. New value columns are always added to the end of the table.
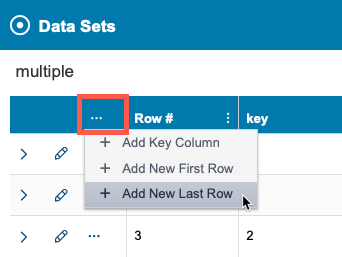
New key columns are added to the beginning of the table (immediately to the right of the Row # column) in alphabetical order according the following precedence:
- Columns starting with a hyphen (-)
- Upper case
- Lower case
About Key and Value Column Names
Column names cannot:
- contain white spaces
- contain non-alphanumeric characters
- start with a digit
- use underscores as the first or last character
If the file contains any of these characters, they will be replaced by underscores when imported into a data set.
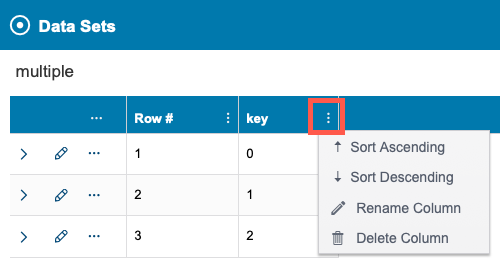
Click on the column actions menu to rename or delete the column. You can also sort how the data is presented by key column values. Sorting does not affect the structure of the data.
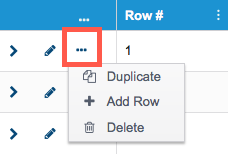
Click the row actions menu to add an inline row, duplicate the data row, or delete the row.
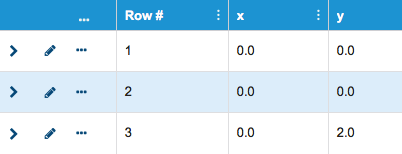
You can expand rows to view the data in the JSON viewer.
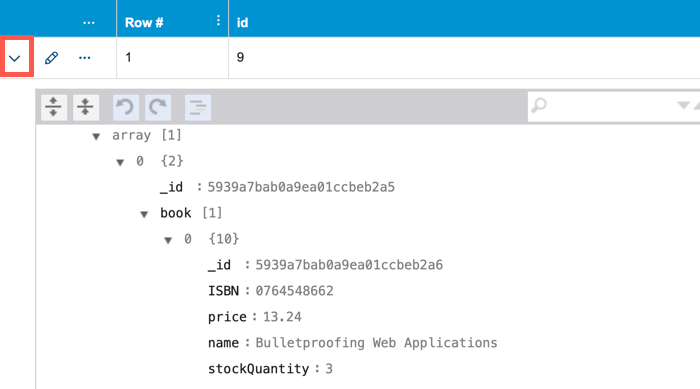
View Null and Exclude Fields
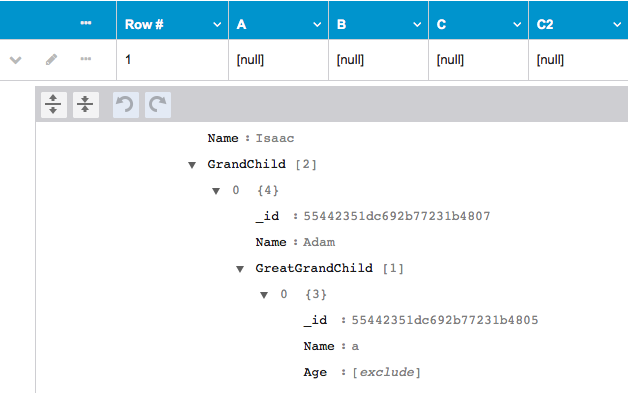
Null and exclude are special values in CTP. If a primitive field was configured to be set to null/exclude, it is represented as [null] / [exclude]. For example, see Age in the screenshot below.
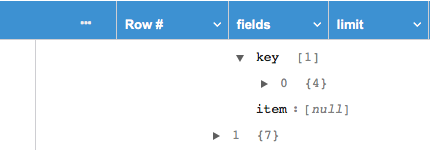
If a primitive list field is set to null/exclude, it is presented as an array of one item with the value [null] / [exclude]. For example, see key in the screenshot below.
If a record list field is set to null/exclude, it is presented as an array of one item with the value [null record] / [exclude record] (to distinguish it from a null/exclude primitive list). For example, see string in the screenshot below.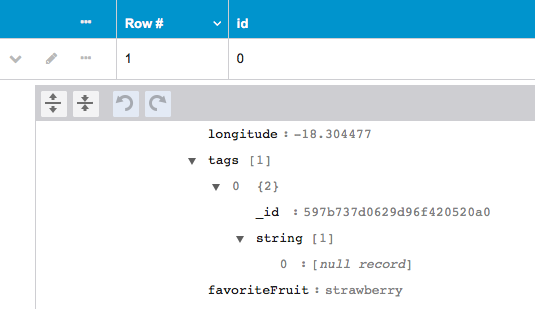
If you want to set a field to null or exclude (so it will not appear in the message when an element is populated from this data source), use [null] or [exclude] while editing.
Modify Data
You can modify values and change the structure of the data set. Click the pencil icon to enable editing.
Locked repositories
If the repository is locked by another user, you will not be able to modify it or delete any of its records.
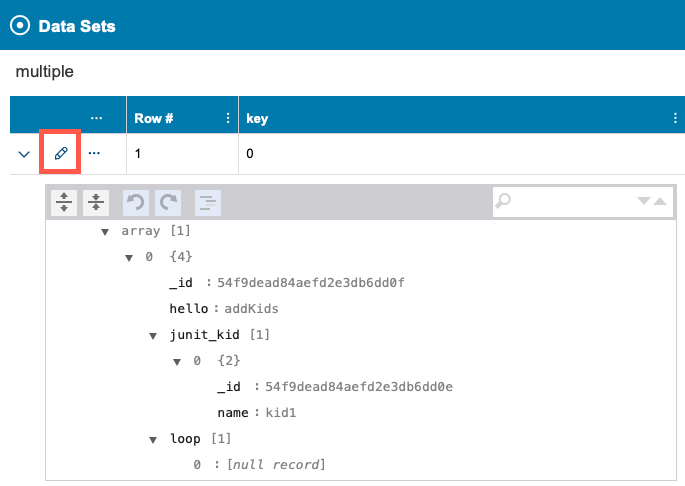
Editable values will become active. You can edit data key values in the table and primitive values in the JSON view editor.
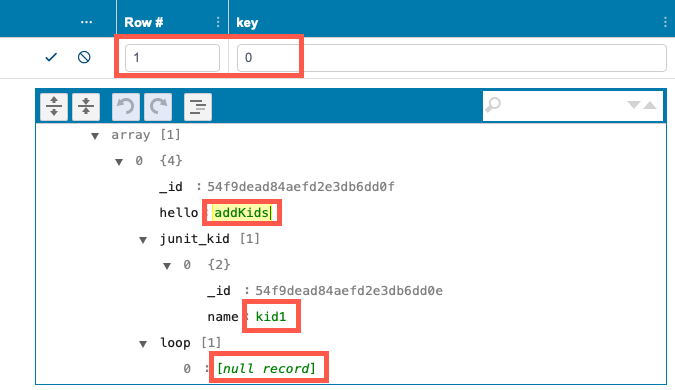
Click the Modify Structure button to make changes to the structure of the data.
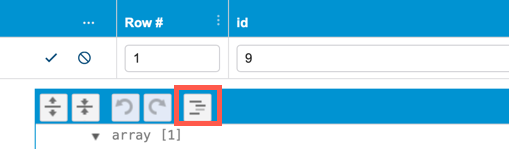
You can perform the following actions when Modify Structure is enabled:
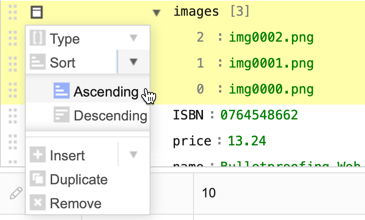
- Click and drag node handles to reorder them.

- Open the actions menu to change the data type, insert new fields, duplicate a field, or delete a field.
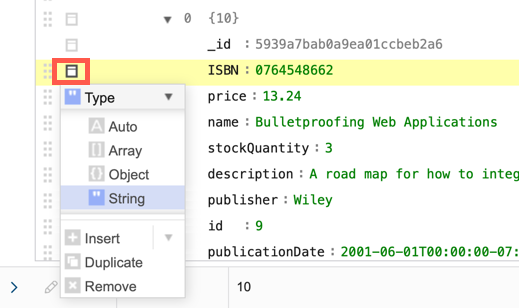
- When adding or modifying arrays or object fields, the Append option appears in the node's actions menu so that you can add children to the record.

- You can also sort children in arrays and object fields.
Click Save when finished.
Creating a Data Set on Import
Only CSV and CSV-formatted files are currently supported for import.
- In the Data tab, choose a repository from the server menu and click the add data set button.
- Specify a name for the data set and a name for the record type name (optional).
- Choose the From CSV File option and click Next.

- Choose the file containing the data when prompted. The uploader detects column headers. By default, the encoding is set to UTF-8. The separator and quote characters are set also to common characters by default. If your file has a different encoding or uses different separator and quotation mark characters, change them in the drop-down menu.

(Optional) Configure how the data is imported. Click in a field in the File options and choose from the available settings. Enable the Trim spaces option to remove extraneous spaces from the data. You can designate a field as a key, value, or both. Keys enable message responders to find the correct row of data to construct responses.

- Click Create when finished configuring the data set. A task is to import the data will be added to the Test Data task queue (see Reviewing Tasks in Test Data). The data set may not appear on the repository or be available immediately. You can continue using CTP while the import task is being processed. A message will tell you when the import is finished.
- Click on the data set to edit the data. See Adding and Modifying Data.